CS240 Note
CS240 final exam Note
List#
- List
- L1-Operating Systems Overview
- L2-Process Management Concepts
- L3-Process Scheduling I
- L4-Process Scheduling II
- L5-Process Scheduling III
- L6-Disk Operation and Scheduling
- L7-Process Creation and Interprocess Communication
- L8-Unix Pipes and Sockets
- L9-Unix Message Queues and Remote Procedure Call
- L10-Threads
- L11-The Mutual Exclusion Problem 互斥问题
- L18-Introduction to Memory Management
- L19 & 20-Memory Management
- L21 & 22 & 23-File Systems
L1-Operating Systems Overview#
操作系统主要任务#
操作系统主要任务有,处理器管理、存储器管理、设备管理、文件管理和作业管理
- Processor Management
- Memory Management
- Device Management
- File Management
- Job Management
L2-Process Management Concepts#
Programs, Processes, Processors#
Program 程序
A program is a collection of instructions specifying a defined sequence of execution. It is the translation of an algorithm into a programming language. 程序是指定定义的执行顺序的指令集合。 它是将算法转换为编程语言的翻译过程。
Processes 进程
A process is an instance of a program in action. It is an operating system abstraction. When the instructions are being carried out, a process exists.
进程是正在运行的程序的一个实例。 它是一种操作系统抽象。在执行指令时,存在一个过程。 程序的可执行模块作为程序映像加载到主存储器(main memory)中,处理器从中获取指令。程序映像(program image)具有特定于特定操作系统和处理器的格式,并且包括任何程序参数、堆栈空间、数据空间和程序代码。
-
A process is an execution context, a collection of kernel managed information needed while it is running.
-
Processes are dynamic entities whose lifetimes range from a few milliseconds to maybe months.
-
Processes may be persistent, implementing system services.
进程是一个执行上下文(execution context),是它运行时所需的内核管理信息(kernel managed information)的集合。 进程是动态实体(dynamic entities),其生命周期(lifetimes)从几毫秒到几个月不等。 进程可能是持久的(persistent),实现系统服务。 操作系统本身可能由多个进程组成,例如进程管理器(process manager)、内存管理器(the memory manager)、文件管理器(the file manager)等。
Blocked Processes 进程阻塞#
正在运行的进程由于提出系统服务请求(如I/O操作),但因为某种原因未得到操作系统的立即响应,或 者需要从其他合作进程获得的数据尚未到达等原因,该进程只能调用阻塞原语把自己阻塞,等待相应的 事件出现后才被唤醒。 A running process that makes a request for system services (such as I/O operations) but for some reason does not receive an immediate response from the operating system, or needs to obtain data from other partner processes has not yet arrived, the process can only call a blocking primitive to block itself, waiting for the corresponding event to appear before being awakened.
Representing Process Abstractions#
- A fundamental task(基本任务) of an operating system is process management – Creating, Controlling, Terminating – Managing the Execution Environment
- For each process, the operating system maintains a process control block (PCB) (过程控制块) or process descriptor (过程描述符) to keep a clear picture of what each process is doing, what point it has reached in its execution and what resources have been assigned to it
Process Control Block PCB 进程控制块#
Process Control Block is used to keep track of the execution context. 过程控制块用于跟踪执行上下文
- Process Identification Data 过程识别数据
- Processor State 处理器状态
- Process Control Data 过程控制数据
Process Lifecycle 进程生命周期#
- The PCB may be moved between different queues over the process lifetime depending on the priority or state of its execution. 根据优先级或执行状态的不同,PCB可以在进程生命周期内的不同队列之间移动。
- serviced using scheduling algorithms 使用调度算法提供服务
System Calls-Communicating with the Operating System 系统调用#
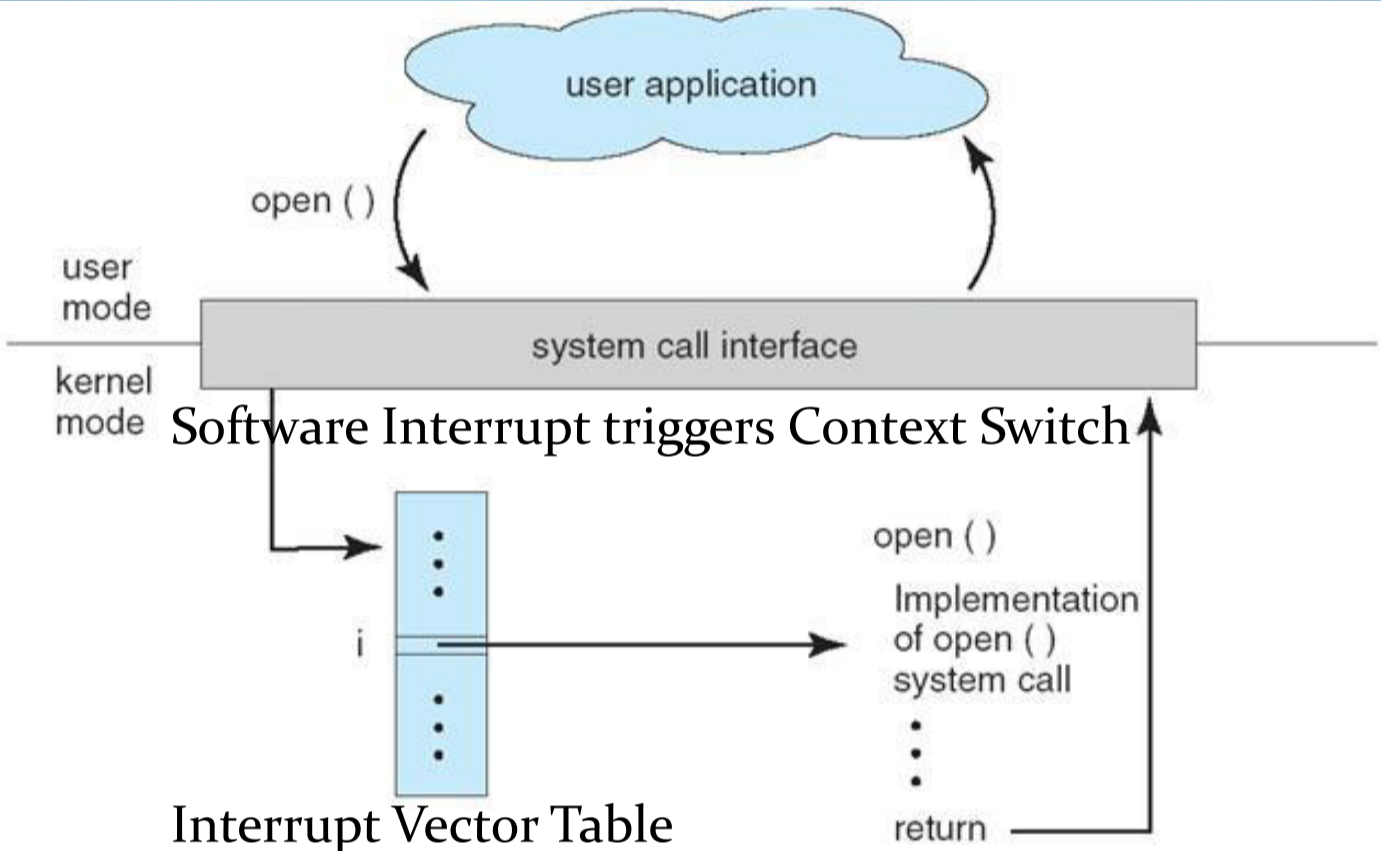
- A special processor instruction known as a software interrupt is the mechanism for doing this. 一种称为软件中断的特殊处理器指令就是实现这一目的的机制。
硬件中断简单来说就是CPU停下当前的工作任务,切换上下文去处理其他事情,处理完后回来继续执行刚才的任务,会有个终端指向表来记录中断信息。
- System Calls are often accessed through wrapper libraries linked with the user space process. 系统调用经常通过包装程序库进行访问
Hardware Interrupt 硬件中断#
- 定义:Interrupts Detected during Instruction Execution Cycle. 在指令执行周期中检测到的中断
- 目的:The Hardware Interrupt mechanism is needed to enable the system to effectively manage a large number of hardware devices efficiently. Polling the status of devices is not efficient. 为了使系统能够有效地管理大量的硬件设备,需要硬件中断机制。轮询设备状态效率不高在指令执行周期中检测到的中断
- prevents one process from hogging the CPU indefinitely. 防止单进程一直占据CPU
- A Hardware Interrupt mechanism is also needed to implement a multitasking environment. 用于实现多任务环境
中断是指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。
L3-Process Scheduling I#
Multitasking 多任务处理 Multiprocessing 多进程处理 Scheduling Algorithm Performance Criteria 调度算法性能标准 Analysis of FCFS vs SJF 分析 FCFS 与 SJF
Multiprocessing 多元处理#
Multiprocessing is the use of more than one CPU in a system, usually separate physical CPUs 多处理是在系统中使用多个 CPU,通常是单独的物理 CPU but the idea may also apply to a single CPU with multiple execution cores 但这个想法也可能适用于具有多个执行核心的单个 CPU
Coordinating Multiprocessing Activity 协调多元处理活动#
Asymmetric multiprocessing 非对称多元处理系统#
one processor, the master, centrally executes operating system code and handles I/O operations and the assignment of workloads to the other processors which execute user processes. 一个处理器,即主处理器,集中执行操作系统代码并处理 I/O 操作以及将工作负载分配给执行用户进程的其他处理器。(适合大小核?)
While this makes it easier to code the operating system functions, in small systems with few processors the master may not have enough slaves to keep it busy, so maximum hardware performance is not achieved.虽然这使得编写操作系统功能更容易,但在处理器较少的小型系统中,主设备可能没有足够的从设备来保持忙碌,因此无法实现最大的硬件性能。
Symmetric multiprocessing 对称多元处理系统#
All processors carry out similar functions and are self scheduling. 所有处理器都执行类似的功能并且是自调度的。
This access contention must be programmed carefully to protect the integrity of the shared data structures. 这种访问争用必须仔细编程以保护共享数据结构的完整性
Process Scheduling Algorithms 进程调度算法#
进程调度算法的指标#
- Processor Utilisation = (Execution Time) / ( Total Time)
- Throughput = Jobs per Unit time
- Turnaround Time = (Time job finishes) - (Time job was submitted)
- Waiting Time = Time doing nothing in a queue
- Response Time = (Time job is first scheduled on CPU) - (Time job was submitted)
Scheduling algorithms can be preemptive or nonpreemptive.
FCFS (First Come First Served)#
在进程调度中,FCFS调度算法每次从就绪队列中选择最先进入该队列的进程,将处理机分配给它,使之投入 运行,直到完成或因某种原因而阻塞时才释放处理机
FCFS is an inherently fair algorithm but performs badly for interactive systems where the response time is important and in situations where the job length differs greatly. FCFS 是一种本质上公平的算法,但在响应时间很重要的交互式系统以及作业长度差异很大的情况下表现不佳。(所有任务都在等待耗时长任务处理完)
SJF (Shortest Job First)#
短作业(进程)优先调度算法是指对短作业(进程)优先调度的算法。短作业优先(SJT) 调度算法从后备队列中 选择一个或若干佔计运行时间最短的作业,将它们调入内存运行;短进程优先(SPF)调度算法从就绪队列中 选择一个估计运行时间最短的进程,将处理机分配给它,使之立即执行,直到完成或发生某事件而阻塞时,才释放 CPU。
SJF is provably the optimal algorithm in terms of throughput, waiting time and response performance but is not fair. 在吞吐量、等待时间和响应性能方面,SJF是可证明的最佳算法,但并不公平。 SJF favours short jobs over longer ones. The arrival of shorter jobs in the ready queue postpones the scheduling of the longer ones indefinitely even though they may be in the ready queue for quite some time. This is known as starvation. SJF偏向于短作业而不是长作业。较短的作业到达准备队列时,会无限期地推迟较长作业的调度,尽管它们可能在准备队列中已经有一段时间了。这就是所谓的饿死。(有可能因为不短进入短作业而一直无法执行长作业)
HRN(Highest Response Ratio Next) Algorithm 高响应比调度算法#
Response Ratio = (Waiting Time) / (Service Time)
- 作业的等待时间相同时,要求服务时间越短,响应比越高,有利于短作业。
- 要求服务时间相同时,作业的响应比由其等待时间决定,等待时间越长,其响应比越高,因而它实现的是先来先服务 FCFS。
- 对于长作业,作业的响应比可以随等待时间的增加而提高,等待时间足够长时,其响应比便可升到很高,从而也可获得 CPU资源。因此,克服了 SJF 的饥饿状态,兼顾了长作业
L4-Process Scheduling II#
Round-Robin 轮询调度#
Round-Robin,轮询调度,该调度策略的用户轮流使用共享资源,不会考虑瞬时信道条件。
why use Round Robin (RR)#
Round Robin is chosen because it offers good response time to all processes, which is important for achieving satisfactory interactivity performance in multitasking systems. 之所以选择轮循,是因为它为所有进程提供了良好的响应时间,这对于在多任务系统中实现满意的交互 性能非常重要。

- Round Robin is a preemptive version of FCFS.
- The quantum can be varied, to give best results for a particular workload.量程可以变化,以便为特定工作负载提供最佳结果。
- Note that the round robin algorithm incurs a greater number of task switches than non preemptive algorithms. 请注意,轮询算法会导致更大的任务切换量相较于非抢占算法的数量
L5-Process Scheduling III#
L6-Disk Operation and Scheduling#
How data is organised and stored on a hard disk?
The surface of each platter is organised as a concentric group of magnetic tracks , on which data can be stored.
Each track is divided into a number of blocks of fixed size called sectors(扇区) in which the data is stored.
Disk sectors refer to the number of fixed size areas that can be accessed by one of the disk drive’s read/write heads, in one rotation of the disk, without the head having to change its position. An intersection of a track and a disk sector is known as track sector. Each sector is uniquely assigned a disk address before a disk drive can access a piece of data. In order to make the disk usable, first it must be formatted to create tracks and sectors. The track sectors are grouped into a collection known as cluster. It refers to the basic allocation unit for storage on a disk. 磁盘扇区指的是一个磁盘驱动器的读写磁头可以访问的固定大小的区域的数量,在磁盘的一次旋转中,磁头不必改变它的位置。磁道和磁盘扇区的交集称为磁道扇区。 在磁盘驱动器能够访问数据之前,每个扇区都被唯一地分配一个磁盘地址。为了使磁盘可用,首先必须将其格式化以创建磁道和扇区。航迹扇区分组成一个集合,称为群集。它是指磁盘上存储的基本分配单元。
Disk Scheduling Algorithms 硬盘调度算法#
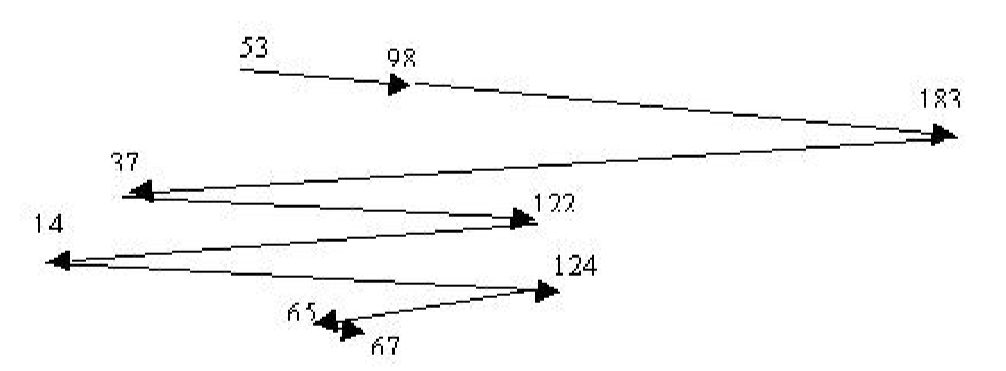
Example Conditions: Say tracks are numbered outer to inner 0-200. Head is currently sitting on track 53 with following track requests in queue. 说轨道从外到内编号为0-200。磁头目前坐在53号轨道上,下面的轨道请求正在排队。 How far does it have to move to service each of the tracks? 它需要移动多远才能为每条轨道提供服务? $$ 98 183 37 122 14 124 65 67 $$
First come first serve FCFS#
这种算法比较公平,但是它通常并不提供最快的服务。
Shortest Seek Time First SSTP#
Choose the request which is closest to the current head position. With this algorithm we would get the following head movements:
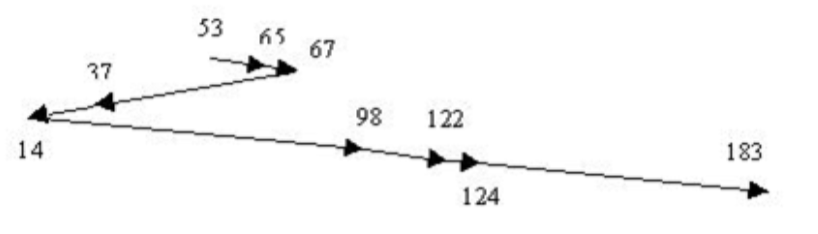
Note that on average, the head will be somewhere around the middle of the disk and that this algorithm therefore favours requests in this area. The outer and inner tracks of the disk may therefore be starved. 请注意,平均来说,磁头会在磁盘的中间位置,因此这种算法更倾向于在这个区域的请求。因此,磁盘的外部和内部轨道可能会被饿死。
SCAN Algorithm#
The head moves in one direction, either to the center or to the outermost track, servicing requests as it passes the corresponding tracks. It then turns around and repeats this in the other direction. 磁头向一个方向移动,要么向中心移动,要么向最外侧的轨道移动,在经过相应的轨道时为请求提供服务。然后它转过身来,在另一个方向重复这一过程。 With this algorithm, assuming the head is moving in the direction of increasing track numbers and tracks numbers are from 0...200, we would get the following head movements:
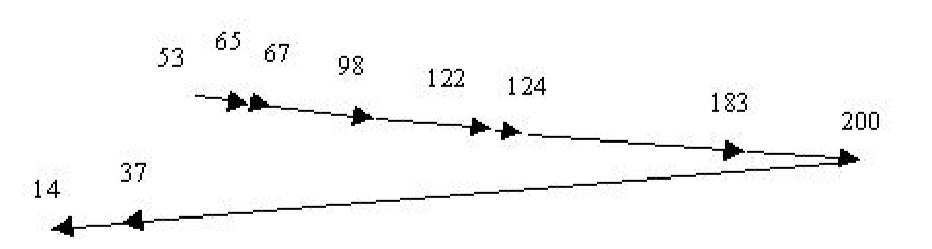
假设请求柱面的分布是均匀的,考虑当磁头移到磁盘一端并且反转方向时的请求密度。这时,紧靠磁头前方的请求相对较少,因为最近处理过这些柱面。磁盘另一端的请求密度却是最多。这些请求的等待时间也最长,那么为什么不先去那里?这就是 C-SCAN 算法的想法。
C-SCAN Algorithm#
The algorithm attempts to regularise the distribution of service offered by SCAN. When the head has completed movement in one direction, it flys back quickly to the start, without scanning the surface, and begins the scan again in the same direction. Each track then has the same time between consecutive visits by the head. 该算法试图使 SCAN 提供的服务分布规律化。当磁头完成一个方向的运动后,它迅速飞回起点,不扫描表面,并在同一方向再次开始扫描。然后,每个轨道在磁头的连续访问之间有相同的时间。
With this algorithm, we get the following head movements:
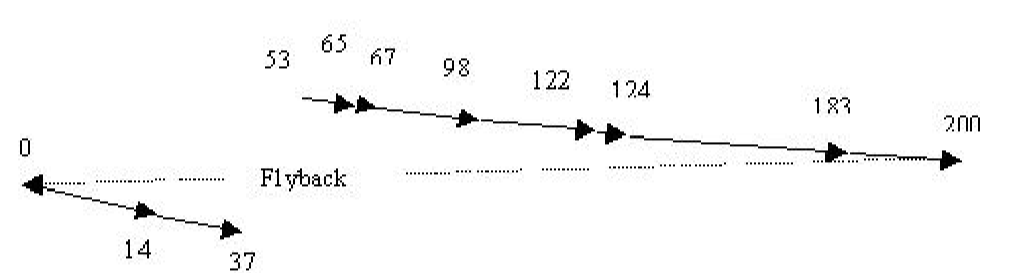
但是实际上我们不需要扫描到尽头,只需要到最远的那个请求就行,LOOK 和 C-LOOK 就是如此。
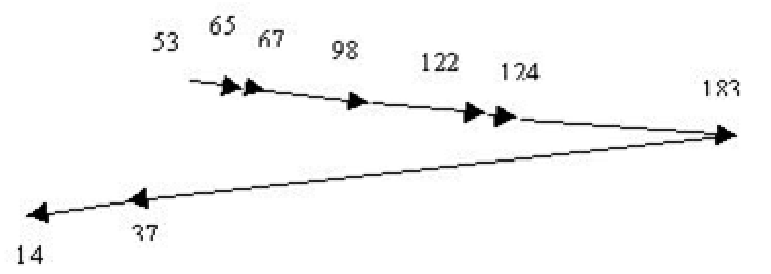
LOOK Algorithm (Elevator Algorithm)#
The LOOK algorithm is the same as SCAN except that where SCAN always continues to the last track in a particular direction before turning around, the LOOK algorithm simply checks to see if there are anymore requests in that direction before turning around. LOOK算法与SCAN算法相同,只是SCAN算法在转身之前总是继续到某一方向的最后一个轨道,而LOOK算法只是在转身之前检查该方向是否还有请求。
With this algorithm we get the following head movements:
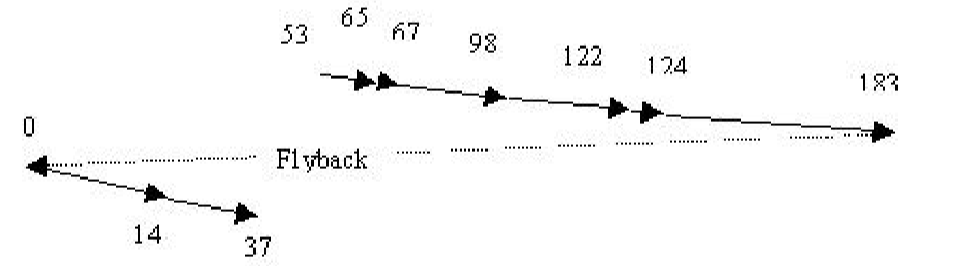
C-LOOK Algorithm#
The C-LOOK algorithm is the same as C-SCAN except that where C-SCAN always continues the last track in a particular direction before flying back, the C-LOOK algorithm simply checks to see if there are anymore requests in that direction before flying back. C-LOOK算法与C-SCAN算法相同,只是C-SCAN算法在飞回之前总是继续某个特定方向的最后一条轨道,而C-LOOK算法只是在飞回之前检查该方向是否还有请求。
With this algorithm we get the following head movements:
L7-Process Creation and Interprocess Communication#
进程创建和进程间通信
- Every process has a unique ID
- Initial process is the Parent and new process is the Chil
在 UNIX 中,正如以前所述,每个进程都用一个唯一的整型进程标识符(pid) Unique integer process identifier 来标识。通过系统调用 fork(),可创建新进程。新进程的地址空间复制了原来进程的地址空 间。这两个进程(父和子)都继续执行处于系统调用 fork() 之后的指令,但有一点不同:对于新(子)进程,系统调用 fork() 的返回值为 0;而对于父进程,返回值为子进程的进程标识符(非零)。
进程间通信Interprocess Communication基本方法:
- By utilising a shared region of memory accessible to all the communicating parties. 通过使用 可被所有通信方访问的内存共享区域
- By using explicit message passing primitives provided by a communication subsystem of the operating system. 通过使用操作系统通信子系统提供的显式消息传递原语。
Reliable and unreliable communication protocols 可靠和不可靠通信协议#
RELIABLE like TCP(Transmission Control Protocol)#
reliable protocols will work together to verify the transmission of data to ensure accuracy and integrity of the data. A reliable system will set up a connection and verify that: all data transmitted is controlled in an orderly fashion, is received in the correct order and is intact. Reliable protocols work best over physical medium that loses data, and is prone to errors. The error correction, ordering and verification mechanisms require overhead in the data packets and increase the total ammount of bandwidth required to transmit data. 运行可靠协议的终端站将协同 工作以验证数据的传输,以确保数据的准确性和完整性。一个可靠的系统将建立连接并验证:所有传输 的数据都以有序的方式进行控制,以正确的顺序接收并且完好无损。可靠的协议在丢失数据且容易出错 的物理介质上效果最好。纠错、排序和验证机制需要数据包中的开销并增加传输数据所需的带宽总量。
UNRELIABLE like UDP(User Datagram Protocol)#
Unreliable protocols make no effort to set up a connection, they don't check to see if the data was received and usually don't make any provisions for recovering from errors or lost data. Unreliable protocols work best over physical medium with low loss and low error rates. 不可靠的协议不努力 建立连接,它们不检查是否收到数据,并且通常不为从错误或丢失的数据中恢复做出任何规定。不可靠 的协议在具有低损耗和低错误率的物理介质上效果最好。
L8-Unix Pipes and Sockets#
Pipes#
- a fast kernel based stream communication mechanism known as a pipe.
- Pipes are FIFO byte stream communication channels. 管道是FIFO字节流通信通道
- unidirectional communication channel, The parent would create the pipe before creating the child so that the child can inherit access to it.
Network Sockets#
- Sockets are the more usual and general purpose means of communication between independent processes and can be used when neither kernel data structures or files can be shared 套接字是独立进程之间更常用和通用的通信方式,可以在内核数据结构或文件都不能共享时使用
- The socket must be bound or associated to some entity (service access point/port) within the communication system 套接字必须绑定或关联到通信系统中的某个实体(服务访问点/端口)
- communication service (e.g TCP/IP) provides the glue for establishing connections between sockets. IP addresses and port numbers are used as a means of identifying the endpoints 通信服务(例如 TCP/IP)为在套接字之间建立连接提供粘合剂。 IP 地址和端口号用作识别端点的一种方式
L9-Unix Message Queues and Remote Procedure Call#
Remote Procedure Call 远程过程调用#
In procedural languages like C, this mechanism is called RPC(Remote Procedure Call), in object oriented environments like JVM, where we are invoking methods on a remote object, it is known as RMI.(Remote Method Invocation)
RPC特点#
- RPC 服务将定义一个接口 interface,允许从该接口自动生成通信存根 stubs to be generated automatically
- RPC机制的实现隐藏在通信存根代码中。然后这些存根与客户端和服务器代码进行静态链接。The implementation of the RPC mechanism is hidden within the communication stub code. The stubs are then linked statically with the client and server code.
Message Queues#
Message queues allow processes to exchange data in the form of whole messages asynchronously. No rendezvous required. 消息队列允许进程以整个消息的形式异步交换数据,不需要请求
Message Queue Manager#
- The operating system maintains the message queue persistently and independently of user processes until it is explicitly unlinked 持久地独立于用户进程维护消息队列,直到明确地解除它的链接 (destroyed) by a user process or the system is shutdown.
- Communicating processes must have access permission(存取许可) to a particular message queue and the message queue API
Summary of Unix Interprocess Communication Mechanisms#
Pipe#
Fast memory based, stream oriented, between related processes 在相关进程之间基于快速内存、面向流
Named Pipes#
Like pipes but uses shared files, useable by unrelated processes Sockets 与管道类似,但使用共享文件,可由不相关的进程使用 Low level internet communication abstraction generally over TCP/IP between unrelated processes 低级互联网通信抽象通常在不相关进程之间通过 TCP/IP
Remote Procedure Call#
Simplifies client/server programming 简化客户端/服务器编程
Message Queues#
Asynchronous whole message communication with priority ordering 具有优先级排序的异步全消息通信
L10-Threads#
Thread Benefits#
-
Simple mechanism to add concurrency 添加并发的简单机制
-
Can be added to an existing language 可以添加到现有语言中
-
Lightweight on Resources, Quick to Create 资源轻量级,快速创建
Multi-threaded Processes 多线程处理#
the model of a single process environment supporting multiple threads of control executing independently at different points within the process’s code.
- PCB Process Control Block
Advantage:
- Better Resource Usage / Quicker to Create
- Improved program performance on multicore多核心 architectures and improved responsiveness for GUI based applications.
- Less problems with network protocols协议 due to server responsiveness
User Space Threads & Kernel Space Threads#
在用户级线程中,有关线程管理的所有工作由应用程序完成,内核意识不到线程存在。通常应用程序从单线程开始,在该线程中开始运行,通过调用线程库中的派生例程创建一个在相同进程中进行的新线程。在内核级线程中,线程管理的所有工作由内核完成,应用程序没有进行线程管理的代码,只有一个到内核级线程的编程接口。
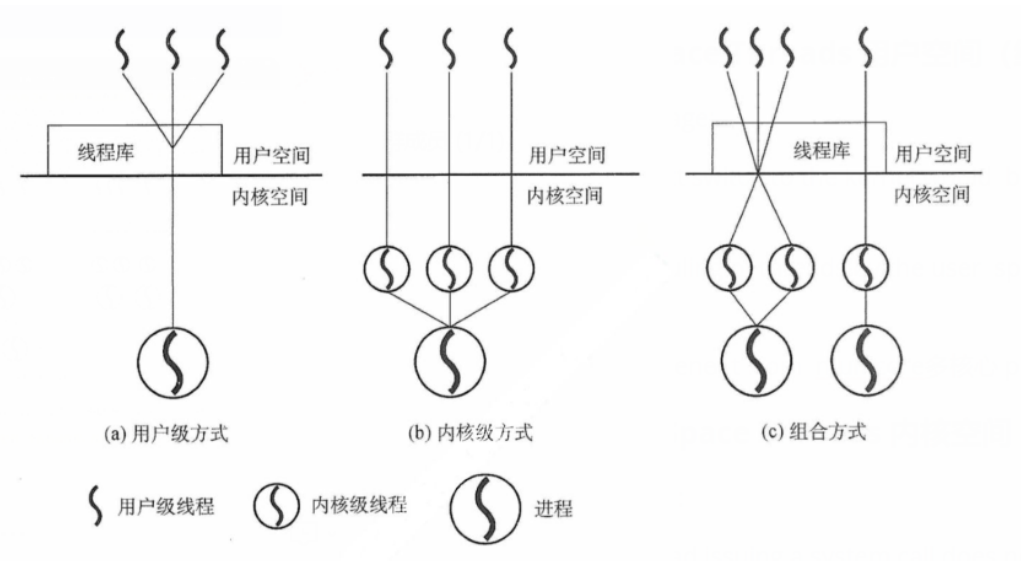
User Space Threads 用户空间(级Level)线程#
Disadvantage:
- context switch to the kernel would block all threads in the process 会阻塞进程中的所有线程
- scheduling of threads by the user space thread library would be non-preemptive 用户空间线程库对线程的调度将是非抢占式的
- can’t benefit from multicore processing. 无法从多核处理中受益。
Kernel Space Threads 内核空间(级Level)线程#
Advantage:
- A thread issuing a system call does not necessarily block all other threads in that process. 不再堵塞
- Threads can be scheduled onto separate CPUs
- Threads compete on an equal basis for CPU cycles and they may be preempted by hardware timers easily
L11-The Mutual Exclusion Problem 互斥问题#
Two Process Solution#
- Mutual Exclusion No two threads can be able to execute simultaneously in the critical code section.
- Progress A thread operating outside the critical section cannot prevent another thread form entering the critical section
- Bounded Waiting 边界等待 Once a thread has indicated its desire 表明要求 to enter a critical section 片段, it is guaranteed 保证 that it may do so in a finite time
单标志法(例如对火车问题的解决)#
A single bowl is used, but initially it contains a rock. If either driver finds a rock in the bowl, he removes it and drives through the pass. He then walks back to put a rock in the bowl. If a driver finds no rock in the bowl when he wishes to enter the pass, he waits. is equivalent to both processes executing the following code:
| Java | |
|---|---|
Peterson's 算法#
为了防止两个进程为进入临界区而无限期等待,又设置了变量turn(Turn can only have one value This condition cannot be true for both processes so no deadlock),每个进程在先设置自己的标志后再设置 —标志。这时,再同时检测另一个进程状态标志和不允许进入标志,以便保证两个进程同时要求进入临界区 时,只允许一个进程进入临界区 (Deadlock free and lockstep free)
| Java | |
|---|---|
N processes#
Bakery Algorithm - Waiting for Critical Section#
这种算法被误解为面包师算法,是一种常用的队列服务方法。线程从一组有序的数字中选择一张票据, 这些数字决定了票据在临界区队列中的位置。-门票是唯一的,有一个服务订单,所以等待是有限的(叫号排队,号码越大约后面)
Look at the tickets of all threads so far and pick one bigger 取号的时候,最大号+1
Busy Waiting 忙碌等待(自旋spinning)#
L18-Introduction to Memory Management#
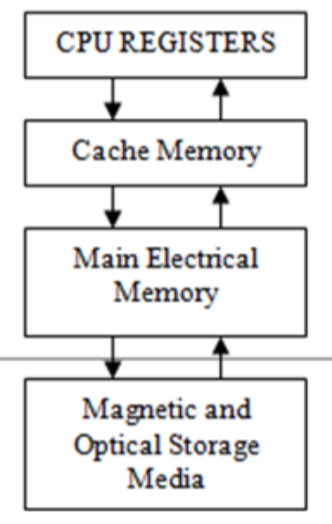
- The memory system is a configuration of different storage technologies that meets a specific cost/capacity/performance objective 内存系统是满足特定成本/容量/性能目标的不同存储技术的配置
- Operating System Memory Manager is concerned with allocation and management of Main Memory and Secondary Storage Swap Space only 操作系统内存管理器只关注主内存和辅助存储交换空间的分配和管理
- The Mapping of Main Memory to the processor caches is done by hardware and not under software control, in order to achieve adequate performance 主内存到处理器缓存的映射由硬件完成,不受软件控制,以实现足够的性能
Memory Management#
没看懂,跳了
L19 & 20-Memory Management#
Managing a Linear Memory Space– Key Ideas#
Bit Map#
- Fixed Sized Data Structure regardless of memory usage 固定大小的数据结构,无论内存使用情况如何
- Allocation efficiency depends on size of bitmap, byte search 分配效率取决于位图大小、字节搜索
- Deallocation very quick 释放非常快
- ½ page internal fragmentation per process 每个进程有1/2 页都是内部碎片
Linked List#
- Dynamic Size, depends on number of free segments 动态大小,取决于空闲段的数量
- Allocation involves possibly long list search if many small segments. 如果有许多小段,分配 可能涉及到长列表搜索
- Deallocation requires complete list analysis to determine neighbour segment mergers. 回收 需要完整的列表分析来确定相邻的部分合并
- No internal fragmentation 没有内部碎片
Buddy System#
- A compromise system allowing dynamically sized partitions 一个允许动态大小分区的妥协系统
- lists are maintained of free memory blocks that are powers of 2 bytes in size. Memory allocation requests are mapped to blocks which are the closest power of 2 in size. 列表由大小为 2 字节的幂的空闲内存块维护。 内存分配请求被映射到大小最接近 2 次方的块。
Page memory (Paged Architecture)#
Paged Architecture supports logical to physical mapping
virtual address > Process Page Table > physical address
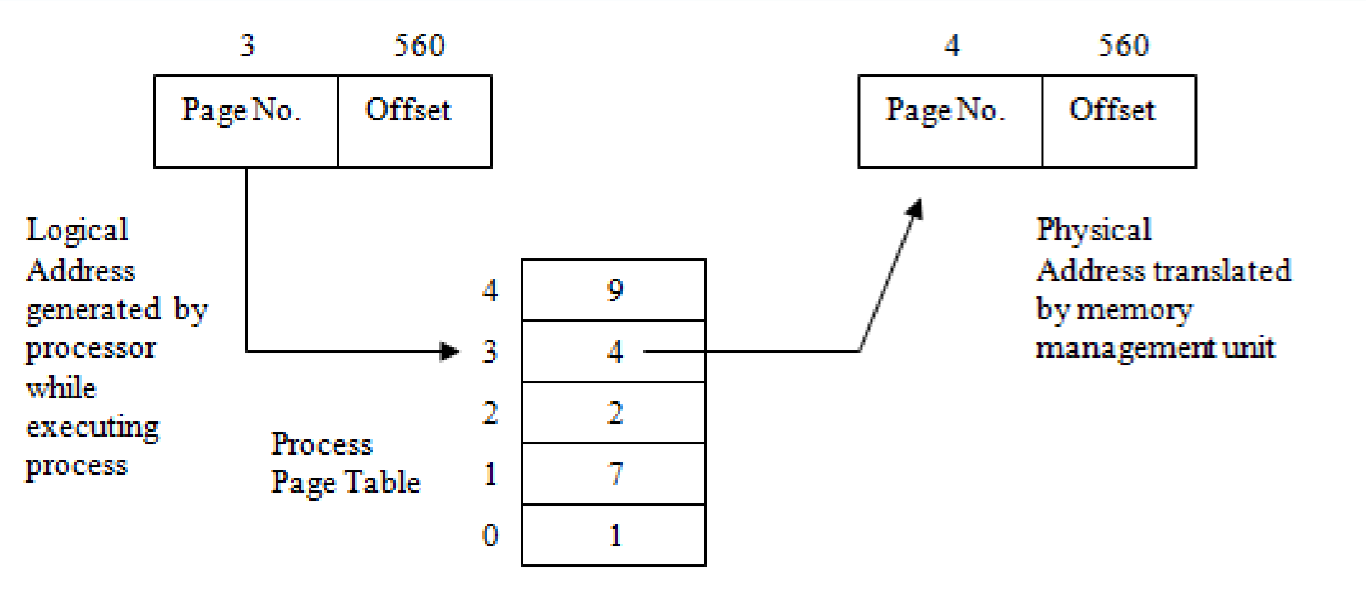
Advantages:
- Protection. As processes only have a logical view of their address spaces.
- do not all have to be adjacent to one another. 并不需要相邻(side by side)
- It is easy to relocate or expand the address space of a process by altering the mapping of pages into its page table. 通过更改页到其页表的映射,可以很容易地重新定位或扩展进程的地址 空间。
Disadvantages:
- Page tables can be large and need to be kept in main memory causing an additional overhead. 页表可能很大,需要保存在主内存中,造成额外的开销。
- two real memory accesses may be needed. Page mapping still slows down the access time to memory slightly. 可能需要两次真正的内存访问。页映射仍然会稍微减慢对内存的访问时间。
- On average approximately ½ a page per process would be wasted. This phenomenon is known as internal fragmentation. 平均而言,每个进程大约会浪费1/2个页面。这种现象被称为内部碎片化。
Page Replacement Algorithms#
First In First Out (FIFO)#
- the algorithm is very easy and cheap to implement. 该算法非常容易实现且成本低廉。
- the behaviour of FIFO is not particularly suited to the behaviour of most programs FIFO 的行为并不特别适合大多数程序的行为
Least Recently Used(LRU) 最近最少使用#
A process has recently used a page then it is likely to need that page again shortly because a lot of our code contains loops. LRU 缓存把最近最少使用的数据移除,让给最新读取的数据。
- selects the page which hasn’t been accessed for the longest time
- require a timestamp to be associated with each page in the page table. 要求一个时间戳与页表中的每个页相关联。
Least Frequently Used (LFU) 最不经常使用#
Replace the page with the smallest reference count during page replacement, because frequently used pages should have a larger number of references. 在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。
- Least frequently used requires a counter to be associated with each page table entry which is incremented whenever a memory access to that page is made. 最少使用需要一个计数器与每个页表条目相关联,每当对该页进行内存访问时,该计数器就会递增。
Belady Anomaly#
When FIFO algorithm is used as the page replacement algorithm, the allocated page increases, but the page faults rate increases. 在使用FIFO算法作为缺页置换算法时,分配的缺页增多,但缺页率反而提高,这样的异常现象称为 belady Anomaly。
L21 & 22 & 23-File Systems#
创建日期: March 16, 2024